クロールジョブの作成(URL指定)
開始URLからリンクを辿り、同一ホスト(開始URLと同じホスト名)のページをクロールします。1
ダッシュボードから「クロール」を選択
2
「新規ジョブ作成」をクリック
3
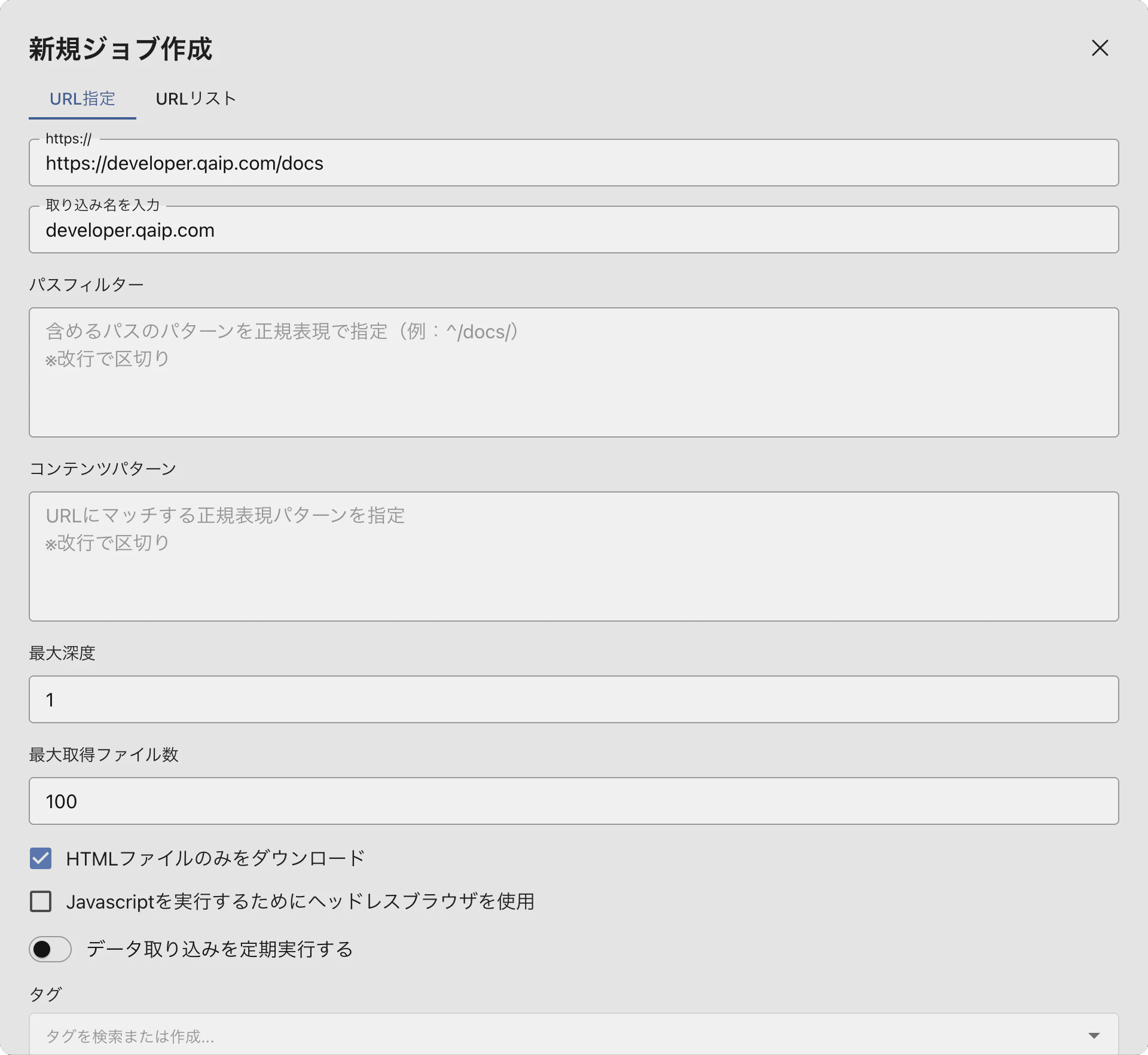
「URL指定」タブで必要な情報を入力
- URL: クロール開始地点のURL
- 最大深度: リンクを辿る階層数(デフォルト: 1)
- 最大取得ファイル数: 取得するファイル数(デフォルト: 100)
クロールジョブの作成(URLリスト)
ダウンロードしたいURLが決まっている場合は、URLリストモードを使用してファイルを直接ダウンロードできます。リンクを辿る必要がないため、異なるドメインのURLも混在させることができます。1
ダッシュボードから「クロール」を選択
2
「新規ジョブ作成」をクリック、「URLリスト」タブを選択
3
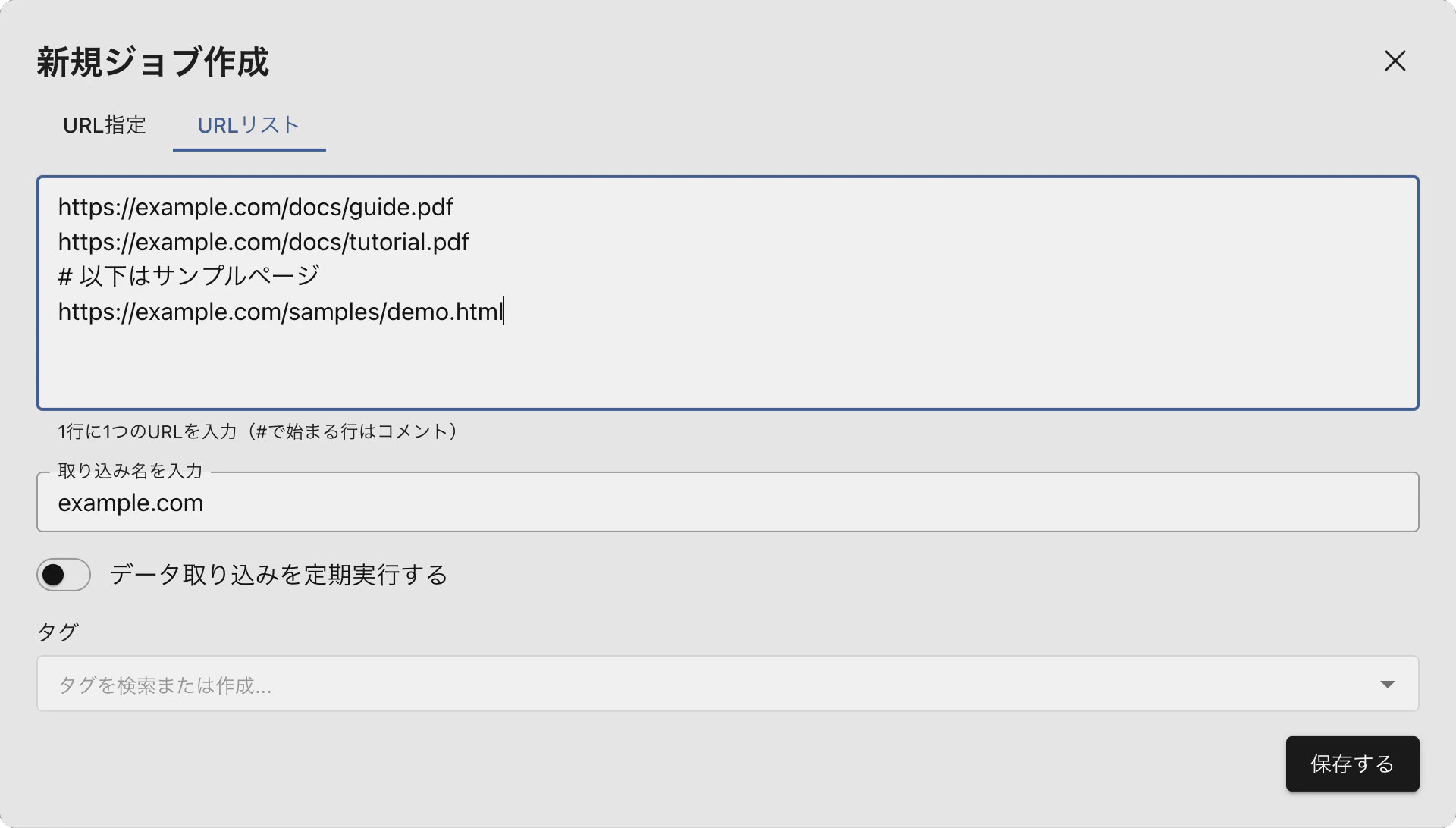
URLリストを入力
1行に1つのURLを入力します。
# で始まる行はコメントとして無視されます。URLリストモードではリンクの探索を行わないため、パスフィルターや最大深度などのクロール設定は不要です。最大取得ファイル数はURL件数に自動で合わせられ、ダウンロード上限として適用されます。
クロール設定の詳細(URL指定モード)
以下の設定はURL指定モードでのみ使用できます。パスフィルター
特定のURLのパスのみを含めたい場合は、正規表現を使用することで辿るリンクを制限できます例
- URL: https://example.com/docs
- パスフィルター:
^/docs/
/docsから辿れる/docs/quickstart.html・/docs/introduction.html・/docs/example.htmlはクロールされます。/docsの上位のディレクトリはクロールされません。/docsから辿れない/docs/orphan.htmlはパスに/docsが含まれていたとしてもクロールされません。パスフィルターに含まれるのはあくまでクロール対象のURLのパスであり、クロール開始地点から辿れるURLに限定されます。
コンテンツパターン
リンクを辿った後に取り込むコンテンツを指定できます:パスフィルターは前処理的に、コンテンツパターンは後処理的に動作します。
HTMLファイルのみをダウンロード
HTMLファイルのみをダウンロードするオプションを有効にできます。ヘッドレスブラウザの使用
javascriptで動的に生成されるコンテンツを取得するためにヘッドレスブラウザを使用できます。クロールファイル内容のダウンロード
/search、GET /contents/{id}、POST /completions の citations で返る content.source_id から、クロール時に保存されたファイル内容をダウンロードできます。
GET /sources/{source_id}/raw はクロール由来の source_id のみ対象です。local_file の source_id は GET /sources/{source_id} で詳細を取得します。
他のデータソースへ広げる場合は、各データソースの永続化済みファイル内容と所有チェックを source_id から解決する必要があります。現時点では crawl のみ対応しています。
大量に取得する場合は
source_id ごとに逐次呼び出します。現時点では一括ダウンロード API はありません。ダウンロードするファイル拡張子
共通でサポートされているファイル形式に加えて、以下の拡張子のファイルがダウンロードされます。- bin
- css
- csv
- gif
- gz
- js
- json
- py
- svg
- xml
- zip